
Дослідники «декодують» об’єкти та ландшафти з уявних образів на основі активності мозку.

Вчені з Національного інституту квантової науки та технологій (QST) та Університету Осаки розробили підхід для розпізнавання за допомогою ШІ складних візуальних образів на основі аналізу функціональної магніторезонансної томографії (фМРТ) мозку. За словами дослідників, підхід можна буде використовувати для вивчення ілюзій, галюцинацій та снів.
Дослідники показали учасникам близько 1200 зображень, а потім проаналізували та кількісно оцінили кореляцію між сигналами мозку та зоровими стимулами за допомогою фМРТ. Карти зв’язків вчені використовували для навчання генеративного ШІ розшифровці та відтворенню уявних образів на основі активності мозку.
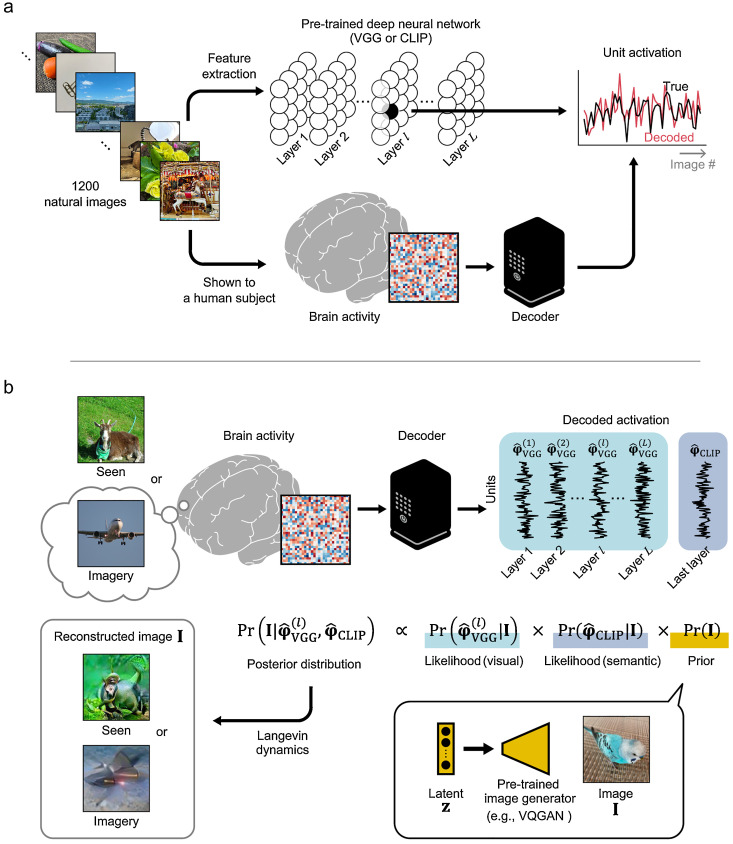
Принцип навчання нейромережі (а) та декодування зображень (б). Ілюстрація: Naoko Koide-Majima et al., Neural Networks
У попередніх дослідженнях різні групи вчених відтворювали зображення, які бачили люди шляхом аналізу активності їх мозку. Але зробити те саме з уявними образами було надто складно. Нечисленні публікації обмежувалися простими зображеннями — літерами чи геометричними фігурами.
Метод, запропонований японськими дослідниками, передбачав відновлення картинок, які учасникам показували під час сканування, і тих, що їх просили представити. Щоправда, для експерименту учасники мали представляти зображення, які їм показували раніше.
Результати показали, що хоча аналіз активності мозку і не відтворює в точності вихідну картинку, проте яскраві зображення, що вийшли, містять чіткі деталі вихідних знімків. Подальший розвиток технології знайдено застосування для вивчення роботи мозку та медичних досліджень, вважають вчені.