
При несподіваному повороті подій чат-бот 1966 року “Еліза” перевершив створений у 2022 році GPT-3.5 у переконанні людей у своїх людиноподібних можливостях. Цей висновок, представлений в недавньому дослідженні, ставить під сумнів точність тесту Тьюрінга, який часто називають золотим стандартом оцінки штучного інтелекту.

Британський математик і криптоаналітик Алан Тьюринг одного разу задумався про те, чи може машина мислити і спілкуватися з людьми як рівний. Його роздуми в 1950 році призвели до створення відомого нині тесту Тьюрінга, який використовувався для оцінки здатності чат-бота видавати себе за людину.
Тест передбачає, що користувач спілкується за допомогою програми як з комп’ютером, так і з людиною, не знаючи, хто є хто. Користувач повинен визначити, виходячи зі своїх відповідей, чи розмовляє він з людиною, чи з чат-ботом. Мета машини – ввести в оману та запропонувати неправильну ідентифікацію.
Якщо “випробуваний” протягом певного періоду часу не може відрізнити програму від людини, вважається, що машина успішно завершила тест. Однак багато експертів вважають цей тест суб’єктивним, оскільки немає єдиної думки щодо того, що вважається успішним проходженням.
На додаток до дискусії, дослідники з Каліфорнійського університету в Сан-Дієго створили веб-сайт для проведення онлайн-тесту Тьюрінга. Мета полягала в тому, щоб визначити, який “співрозмовник” найкраще може видати себе за людину: моделі штучного інтелекту GPT-4, GPT-3.5, ELIZA або група людей. Результати були опубліковані в архіві препринтів arXiv.
В експерименті взяли участь 652 учасники, які більше тисячі разів взаємодіяли через веб-сайт з трьома моделями штучного інтелекту (GPT-4, GPT-3.5, ELIZA) або іншими людьми. Потім вони повинні були повідомити, чи спілкувалися вони з людиною або чат-ботом.
- Бетонні плити з візерунком орігамі знижують витрату бетону і сталі вдвічі
- Вчені створили найміцніший сплав, відомий людству
- Вчені створили штучний інтелект, який здатний жартувати
Дослідження показало, що учасники правильно ідентифікували людських “співрозмовників” в 63% випадків, але в 37% випадків приймали їх за ботів. GPT-4 та GPT-3.5 переконали учасників у їх людській ідентичності у 41% та 14% випадків відповідно. Дивно, але” старожил “ELIZA, чат-бот 1966 року, створений американським вченим Джозефом Вайзенбаумом для імітації бесіди психоаналітика, домігся успіху в 27% випадків, значно перевершивши” більш молодого ” GPT-3.5, всупереч очікуванням дослідників.
Успіх Елізи пояснювався трьома факторами:
1. Типово консервативні відповіді Елізи створювали враження незговірливої співрозмовниці, допомагаючи приховати її штучну природу і звести до мінімуму дезінформацію.
2. Елізі бракувало якостей, які зазвичай асоціюються з сучасними мовними моделями, таких як готовність допомогти, дружелюбність і багатослівність.
3. Учасники сприйняли Елізу як” занадто бідну, щоб бути моделлю штучного інтелекту”, що змусило їх припустити, що вони спілкуються з людиною.
Під час сесій учасники вступали в невимушені бесіди зі своїми “співрозмовниками”, перевіряючи їх знання і думки про поточні події, спілкуючись на іноземних мовах і часто звинувачуючи їх в тому, що вони є моделями штучного інтелекту, тим самим чинячи психологічний тиск.
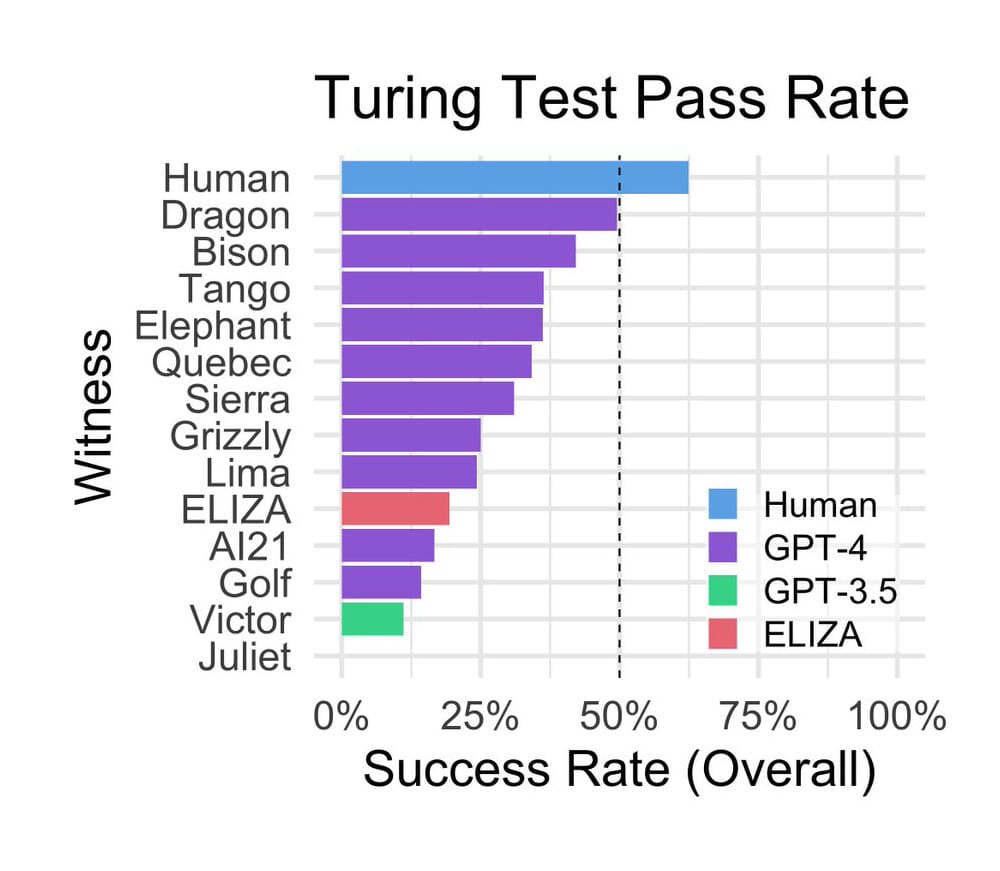
Гістограма успішності виконання тесту Тьюрінга, проведеного американськими вченими / © Cameron Jones
Гістограма з дослідження американських вчених ілюструє показники успішності тесту Тьюринга. Процес прийняття рішень в першу чергу ґрунтувався на манері поведінки і емоційних рисах “співрозмовника”, а не виключно на передбачуваному інтелекті. Користувачі відзначали, коли відповіді були занадто формальними або неформальними, їм не вистачало індивідуальності або вони здавалися загальними.
Автори визнали деякі обмеження свого дослідження, включаючи невеликий розмір вибірки та відсутність стимулів для учасників, які могли вплинути на їх щирість.
Результати також ставлять під сумнів надійність тесту Тьюрінга, особливо враховуючи продуктивність ELIZA. Теоретично результати ELIZA повинні були бути гіршими, ніж GPT-3.5. Дослідники підкреслили, що їхні висновки не обов’язково означають, що тест Тьюрінга повинен бути відхилений; він залишається актуальним і життєздатним.
Що стосується GPT-3.5, то це базова модель, безкоштовна версія ChatGPT, розроблена OpenAI спеціально для того, щоб не видавати себе за людину, що може частково пояснити її меншу ефективність в експерименті.